Опубликовано
- 3 мин чтения
Быстрый способ записать большой массив данных в SQL Server

Последние несколько недель максимально погружен в работу, поэтому публикаций не так много. Но появился интересный кейс, о котором хочется рассказать.
Задача
Нужно было скачать большие csv-файлы, прочитать их, отфильтровать нужные строки и загрузить в базу данных. Под большими я имею в виду файлы по 0,5–1 ГБ – это месячные отчёты от облачных провайдеров о расходах.
Это стандартная ETL-задача. Сложность была в том, что у подов в нашем Kubernetes-кластере ограничение по памяти на 250 МБ. Можно было просто поднять лимит, но это слишком просто и неинтересно. Я решил попробовать сделать всё с минимальными затратами памяти.
Загрузка файлов
Это самый простой этап. Microsoft Azure, Amazon Web Services и Google Cloud Platform позволяют читать данные в виде потоков. То есть не нужно загружать целиком.
Обработка данных
Дальше нужно было разархивировать csv-файлы и прочитать их. Для распаковки использовался встроенный класс GZipStream. Для чтения csv-файлов использовал стороннюю библиотеку Sylvan.Data.Csv.
Вставка в данных в хранилище
В качестве хранилища мы используем SQL Server, поэтому примеры ниже актуальны только для этой БД.
Самый очевидный способ – обычный INSERT. Но если данных много, такой подход занимает неприлично много времени:
using var connection = new SqlConnection(ConnectionString);
connection.Open();
foreach (var row in data)
{
using var cmd = connection.CreateCommand();
cmd.CommandText = "INSERT INTO Table ...";
cmd.Parameters.AddWithValue("@SomeColumn", row.SomeColumn);
cmd.ExecuteNonQuery();
}Для ускорения можно воспользоваться массовой вставкой (bulk insert). В SQL Server это делается через класс SqlBulkCopy из Microsoft.Data.SqlClient.
Практически во всех примерах с SqlBulkCopy которые я видел, применялся подход с использованием DataTable. Суть его в том, что сперва заполняют буфер в виде DataTable, а потом вставляют его в базу данных.
const int batchSize = 250;
using var connection = new SqlConnection(ConnectionString);
connection.Open();
var table = new DataTable();
for (int i = 0; i < data.Length; i += batchSize)
{
table.Clear();
int count = Math.Min(batchSize, data.Length - i);
for (int j = 0; j < count; j++)
{
var row = data[i + j];
table.Rows.Add(row.A, row.B, row.C);
}
using var bulk = new SqlBulkCopy(connection)
{
DestinationTableName = "Table",
BatchSize = batchSize
};
bulk.WriteToServer(table);
}Но мало кто знает, что SqlBulkCopy позволяет вставлять данные потоком через IDataReader. Но, к сожалению, в .NET нет стандартной реализации, позволяющей удобно работать с коллекциями IEnumerable<T> или IAsyncEnumerable<T>. Поэтому приходится городить велосипеды, либо использовать сторонние библиотеки. Например, есть библиотека Bulk Writer от Джимми Богарта.
using var reader = new MyDataReader(_arr);
using var connection = new SqlConnection(ConnectionString);
connection.Open();
using var bulk = new SqlBulkCopy(connection)
{
DestinationTableName = "Table",
EnableStreaming = true
};
bulk.WriteToServer(reader);Бенчмарки
Я написал небольшой бенчмарк, чтобы сравнить три подхода:
- Обычный INSERT, построчно.
- SqlBulkCopy с DataTable.
- SqlBulkCopy с IDataReader.
Результаты сравнения по скорости выполнения и использованию памяти ниже.
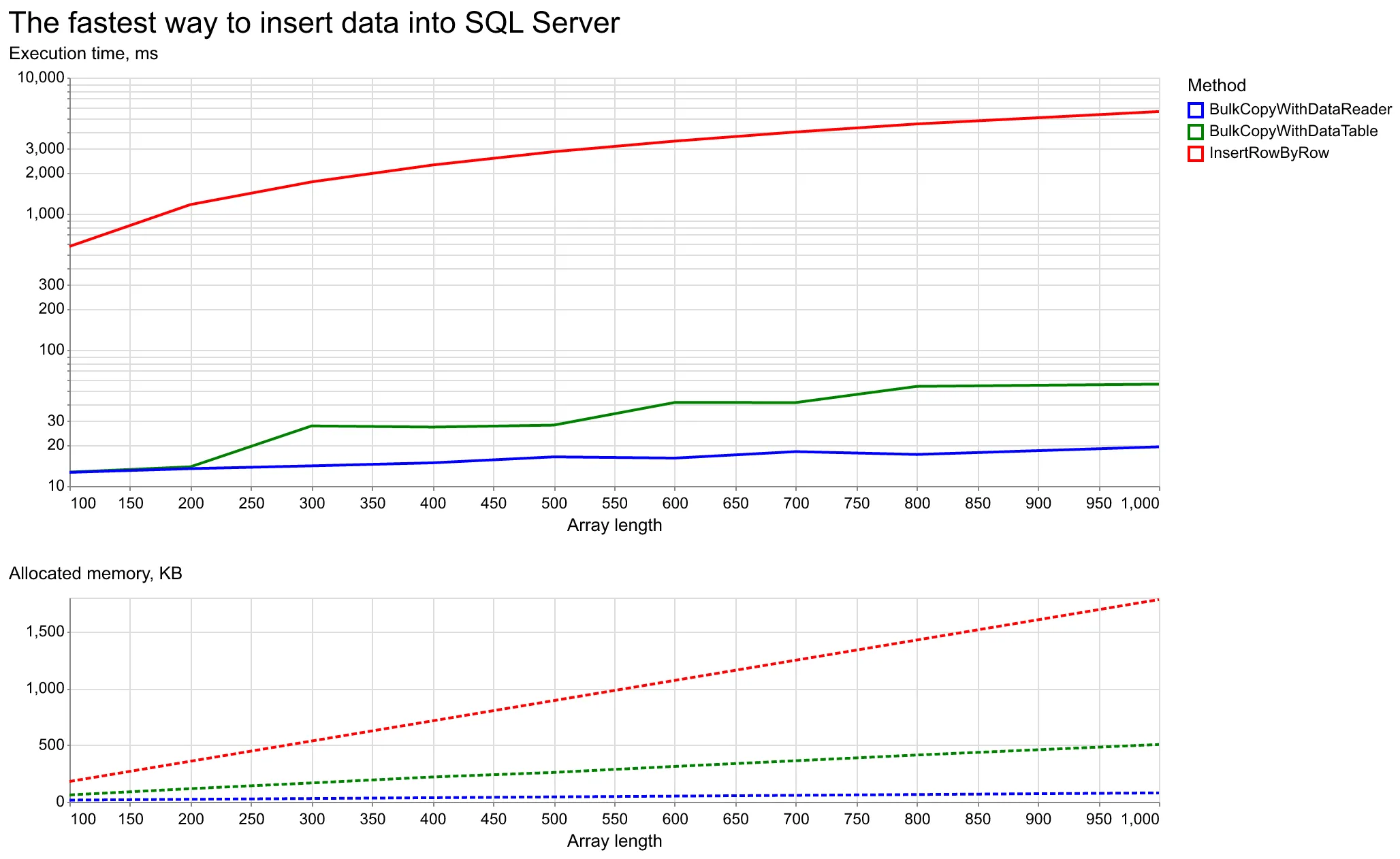
График сравнения производительности
Ожидаемо, построчная вставка данных самая медленная. К тому же, из-за вызова connection.CreateCommand() на каждой итерации и создания SqlCommand, этот способ потребляет больше всего памяти.
SqlBulkCopy с DataTable намного лучше в плане производительности и потребления памяти, но реализация IDataReader ещё быстрее.
На реализацию с DataTable влияет размер буфера. Его значение в бенчмарке – 250 строк. При небольших объёмах разница во времени почти не заметна. Но чем больше данных, тем сильнее выигрывает SqlBulkCopy с IDataReader.
Выводы
Для эффективной загрузки больших данных в SQL Server лучше всего использовать потоковую вставку через SqlBulkCopy и IDataReader. Это намного быстрее и требует меньше памяти, чем стандартный INSERT или даже SqlBulkCopy с DataTable.