Published on
- 1 min read
How data affects performance

I’d like to show how much the way you initialize data can impact the performance of your code.
Let’s take a simple synthetic example:
- Arrays
t1andt2store transaction data. - There are two methods:
Setup1andSetup2.Setup1initializest1andt2using two separate for-loops.Setup2initializes both arrays using a single loop.
- The
Summethod calculates the sum of elements in eithert1ort2.

Which initialization method results in faster execution of Sum(t1) + Sum(t2)?
So the question is: which setup makes Sum(t1) + Sum(t2) faster?
The correct answer: It’s faster if you initialize the arrays using two separate for loops.
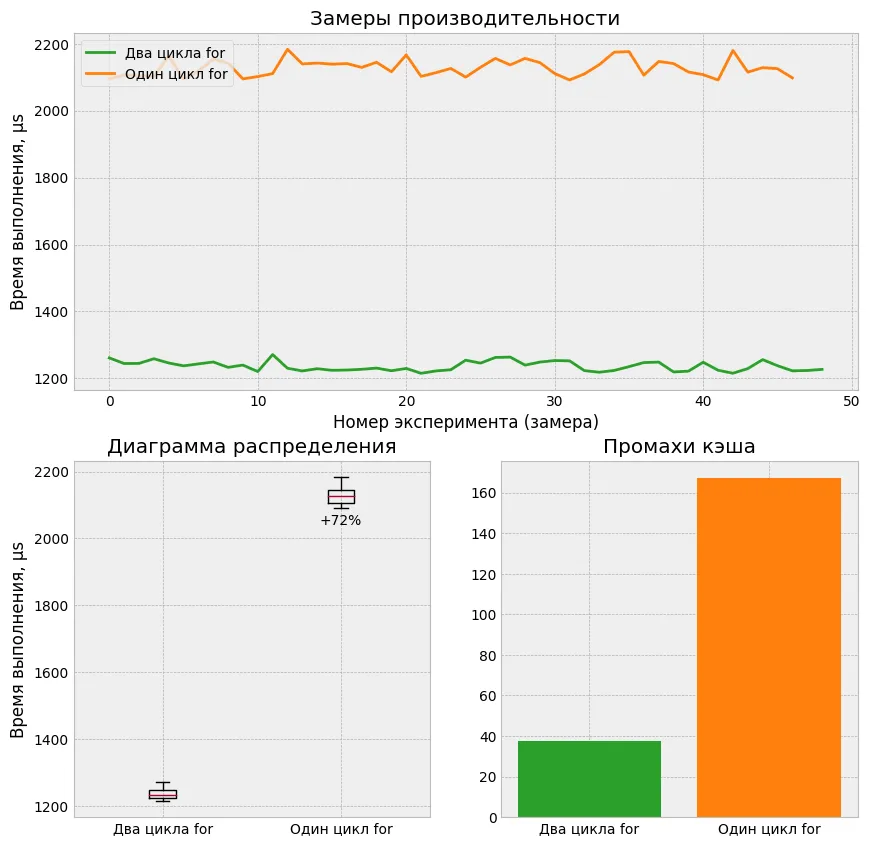
Benchmark results: two separate loops perform better
Why is that? It all comes down to CPU cache behavior.
I’ve written about this before — back then I compared two different algorithms working on the same matrix. This time, the algorithm stays the same, but the data layout in memory changes based on how we initialize it.
If we initialize t1 and t2 using a single for loop, the memory layout will look something like this:
t1[0], t2[0], t1[1], t2[1], t1[2], t2[2], ...When Sum(t1) starts, it accesses t1[0]. But memory gets loaded into cache in blocks (cache lines), typically 64 bytes per block on most CPUs. So when t1[0] is loaded, some neighboring t2 values are loaded too — which are not needed for this calculation. This causes more cache misses.
Now, if we initialize t1 and t2 in separate loops, memory layout becomes:
t1[0], t1[1], t1[2], ... t2[0], t2[1], t2[2], ...This layout gives us better data locality, meaning more of the loaded cache lines contain only the data we need. As a result, the number of cache misses is reduced, and performance improves.