Опубликовано
- 2 мин чтения
PostgreSQL vs TimescaleDB: сравнение производительности

TimescaleDB — популярное расширение PostgreSQL для работы с временными рядами (time-series). В нём есть функционал, позволяющий оптимизировать хранение данных и запросы к ним.
В этой статье я сравню производительность TimescaleDB и PostgreSQL с тестовым аналитическим запросом.
Установка и запуск TimescaleDB в Docker
У TimescaleDB есть готовый Docker образ. Конфигурация аналогична обычной базе Postgres.
# docker-compose.yml
services:
timescaledb:
container_name: timescaledb
image: timescale/timescaledb:latest-pg17
restart: unless-stopped
shm_size: 1g
ports:
- 5432:5432
environment:
POSTGRES_DB: 'timescaledb'
POSTGRES_USER: 'sa'
POSTGRES_PASSWORD: 'qweQWE123!!'
PGDATA: /var/lib/postgresql/17/docker
volumes:
- timescaledb_data:/var/lib/postgresql
volumes:
timescaledb_data:Запускаем базу командой:
docker compose -f docker-compose.yml up -dСоздание hypertable в TimescaleDB
Таблицы в TimescaleDB называются hypertables. Они создаются как обычные Postgres таблицы с небольшим дополнением.
CREATE TABLE billing_data (
billed_cost numeric(25,15),
charge_date timestamptz,
resource_id int4)
WITH (
-- Указываем, что это hypertable
timescaledb.hypertable = true,
-- Разбиваем данные на части (chunks) размером в 1 день
timescaledb.chunk_interval='1 day',
-- Группируем данные по ресурсу
timescaledb.segmentby='resource_id'
-- Сортируем данные по дате
timescaledb.orderby='charge_date'
);Что такое hypertable?
Hypertable — это специальный тип таблицы TimescaleDB, который автоматически разбивает данные на части (chunks), оптимизирует их хранение и доступ для аналитических запросов.
Как работает сегментирование данных в hypertable?
TimescaleDB может использовать колончатое хранение данных (Hypercore), автоматически разбивает таблицу на chunks и поддерживает его в актуальном состоянии. Картинка взята из документации TimescaleDB.
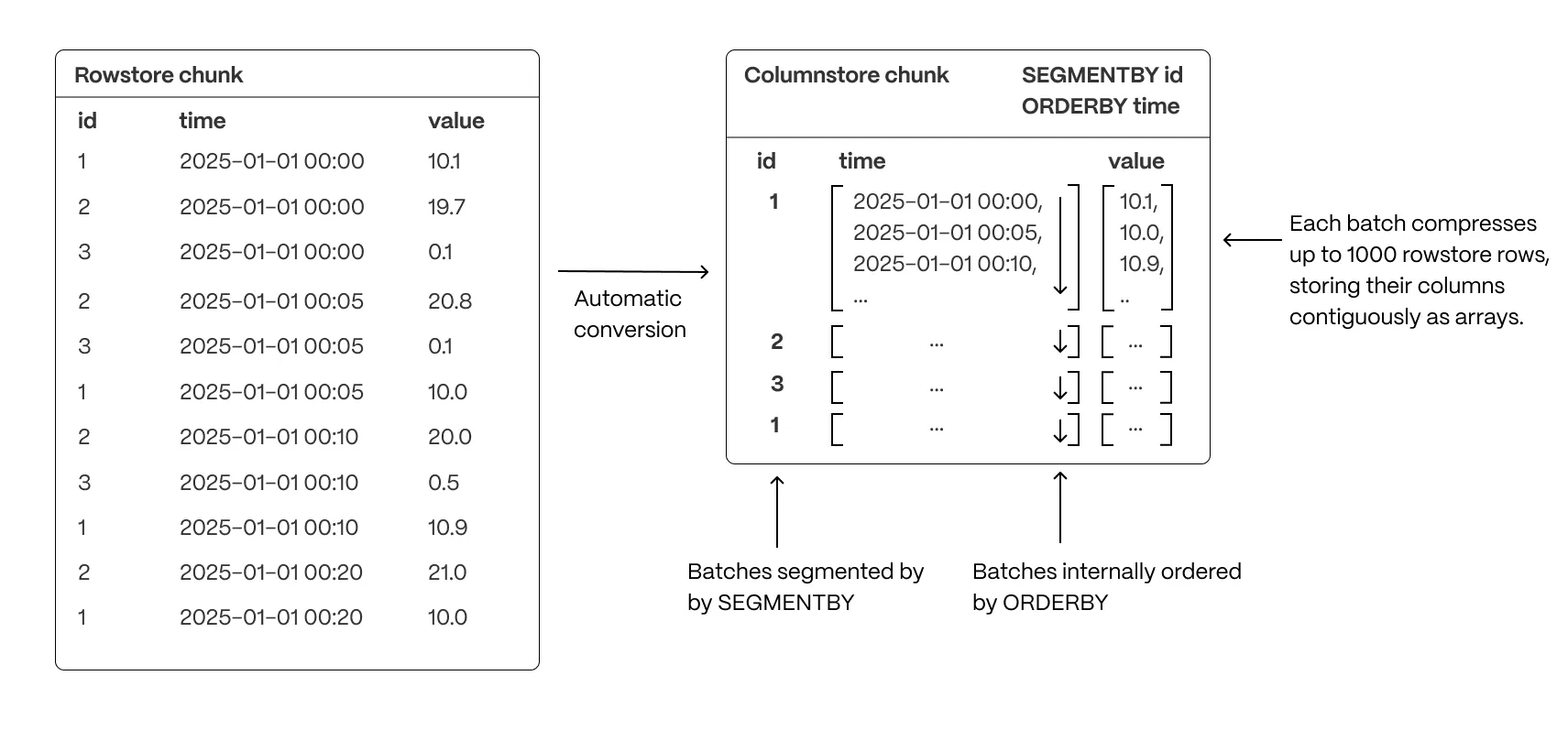
При достаточном объёме данных и низкой кардинальности (небольшом количестве уникальных ресурсов), производительность аналитических запросов на hypertable может быть значительно выше, чем на обычной таблице Postgres. Достигается это за счёт высокой плотности данных и оптимизации доступа к ним.
Бенчмарк: сравнение TimescaleDB и PostgreSQL
В тестовом аналитическом запросе я считал ежедневные траты облачных ресурсов за последние 30 дней.
Для замеров я использовал библиотеку BenchmarkDotNet. Исходный код бенчмарка доступен в моём репозитории на GitHub.
-- Postgres
SELECT
date_bin('1 day', charge_date, TIMESTAMP 'epoch') AS day,
resource_id,
SUM(billed_cost) AS total_cost
FROM billing_data
WHERE charge_date >= now() - interval '30 days'
GROUP BY day, resource_id
-- TimescaleDB
SELECT
time_bucket(INTERVAL '1 day', charge_date) AS day,
resource_id,
SUM(billed_cost) AS total_cost
FROM billing_data
WHERE charge_date >= now() - interval '30 days'
GROUP BY day, resource_idЧем time_bucket отличается от date_bin?
Функции time_bucket и date_bin похожи. Они позволяют группировать данные по произвольным интервалам времени. Однако time_bucket оптимизирован для работы с hypertable и может обеспечить лучшую производительность в TimescaleDB.
Результаты бенчмарка
Результаты бенчмарка на графике ниже. Ось Y — медианное время выполнения, ось X — количество ресурсов в таблице.
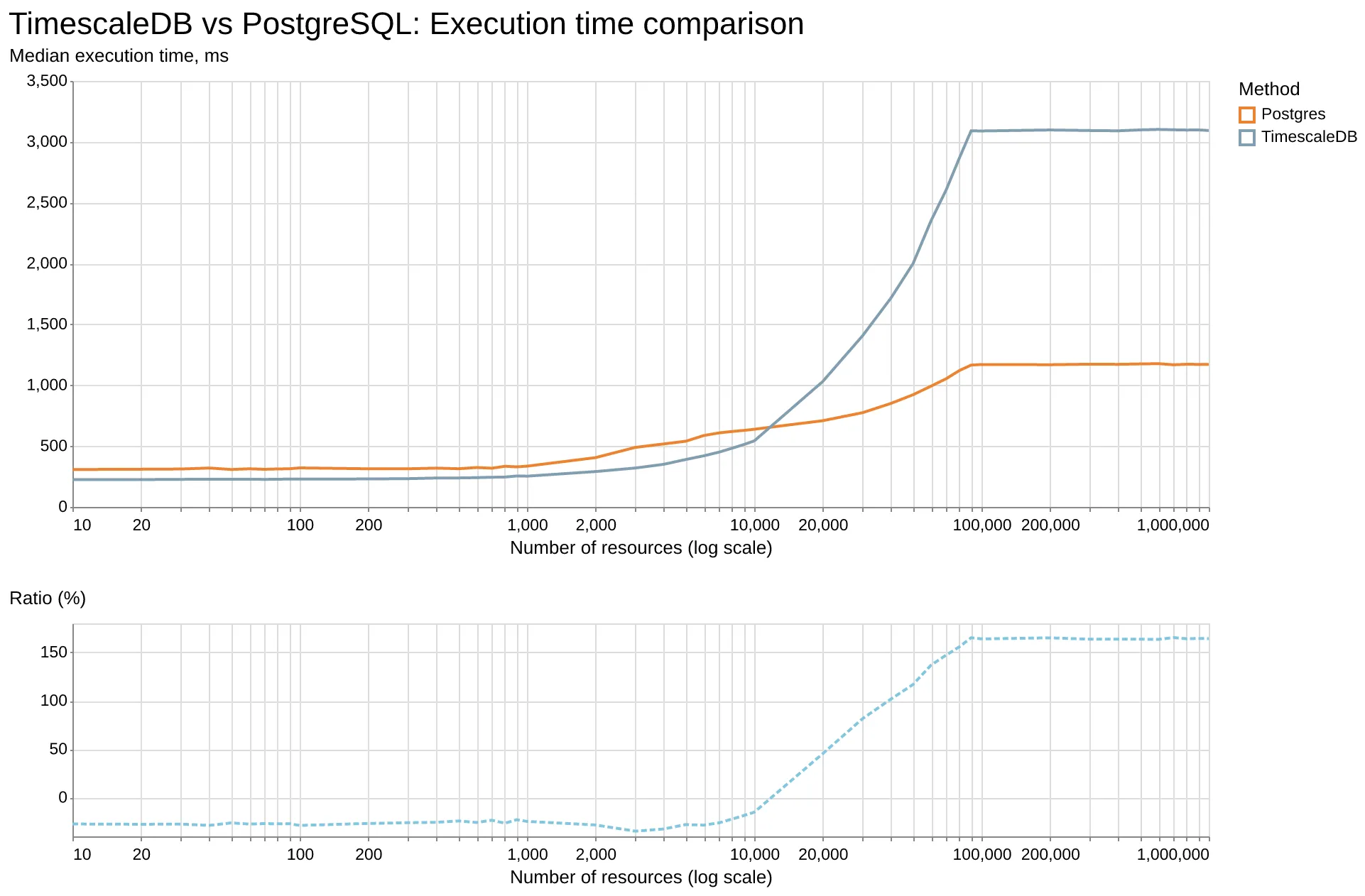
Размер таблицы был фиксированным — 1 млн строк и я изменял только кардинальность путём увеличения количества уникальных ресурсов от 10 до 1 млн. То есть значение кардинальности зависело от соотношения уникальных ресурсов к количеству данных.
Как видно из результатов, производительность TimescaleDB на 15% - 28% лучше при низкой кардинальности (до около 10 000 уникальных ресурсов, или около 100 строк данных на ресурс).
Если кардинальность выше (более 20 000 уникальных ресурсов), время выполнения запроса становится на 45% - 165% хуже.
Заключение
TimescaleDB хорошо подходит для аналитических запросов, если данные имеют низкую кардинальность и достаточный объём. В таких случаях он может обеспечить значительное улучшение производительности по сравнению с обычным Postgres.
В следующих постах я поэкспериментирую с другими данными и запросами, чтобы понять, в каких сценариях TimescaleDB может быть особенно полезен.